商用システムに携わるようになってから、クリーンアーキテクチャとはなんぞや?という疑問をずっと持っていました。
ただ、クリーンアーキテクチャに関する記事を読んでみても正直専門用語が多すぎて全くわけが分からず、理解を断念していました。
本記事ではクリーンアーキテクチャを0から理解することを目標としています。
できるだけ優しく直感的に分かる形で書いていこうと思うのでどうぞお付き合いください。
本記事で扱うコードは以下のrepositoryに入っているので参考にしていただければと思います。
なお、実装はtypescriptで行っており、階層的にはドメイン層とインフラストラクチャ層のみを実装しています。
クリーンアーキテクチャを理解するための流れ
はじめにクリーンアーキテクチャを理解するまでの流れを説明します。
初学者がクリーンアーキテクチャを簡単に理解できないのは以下のような要因があるためだと思います。
- 前提となっているドメイン駆動設計(DDD)やSOLID原則を理解できていない
- 用語が多い
- 実装の柔軟性が高いために人によって実装がぜんぜん違う
なので、今回はなるべく専門用語を使わず、誰もが分かりやすいであろう3層アーキテクチャからから話を初めてボトムアップ式にクリーンアーキテクチャを理解していくことを目指したいと思います。
とはいえ、そんなにたくさんのことを理解する必要があるのかというとそんなこともなく、実際は3層アーキテクチャ、レイヤードアーキテクチャ、SOLID原則、DDDあたりが理解できれば割りとすんなりクリーンアーキテクチャまで手が届くと思います。
理解の順番としては以下のような感じです。
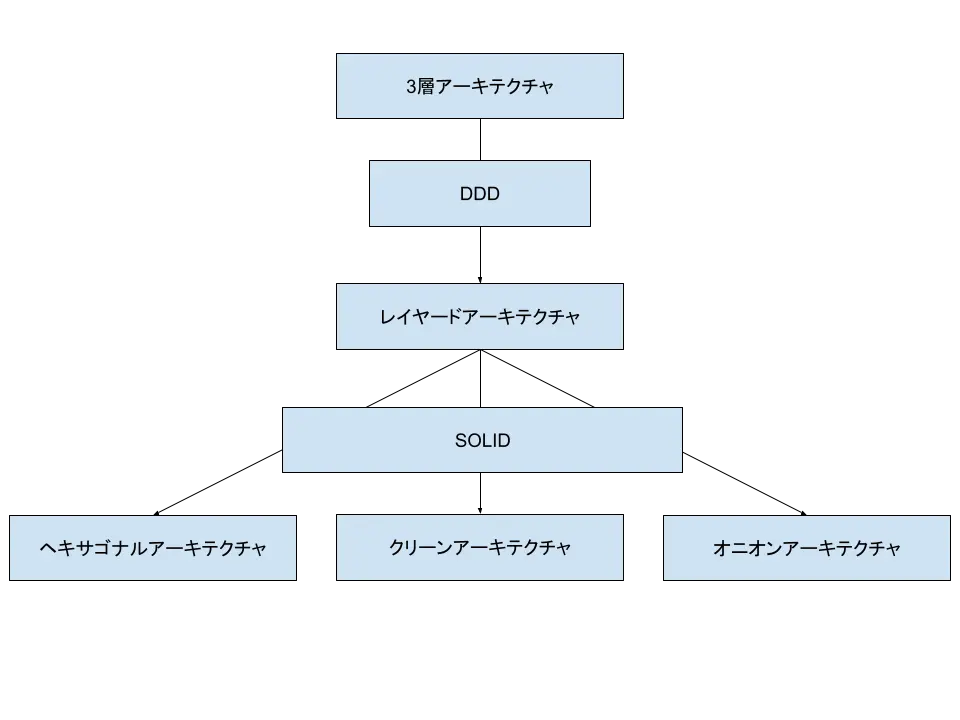
それではまず3層アーキテクチャの説明から始めていきます
3層アーキテクチャ
3層アーキテクチャは見た目、ロジック、データを分離した設計のことです。
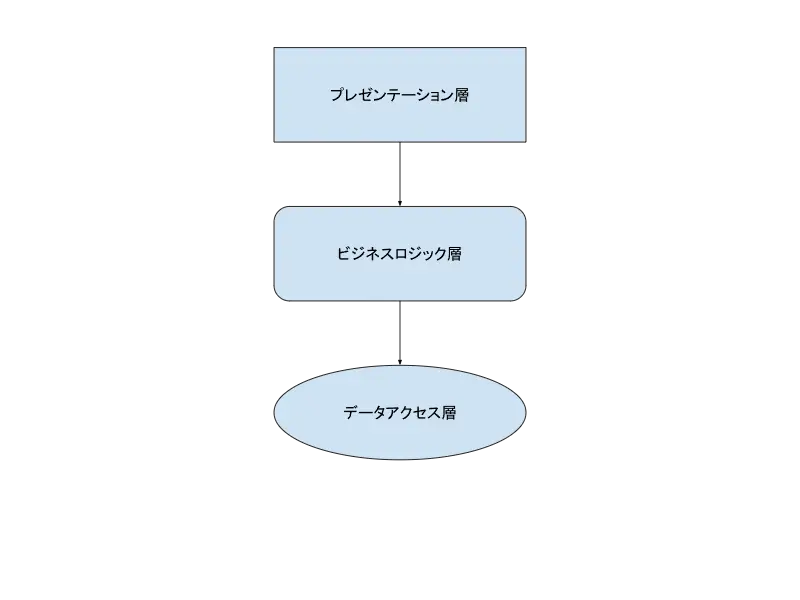
これはサーバーでいうとwebサーバー、アプリケーションサーバー、DBサーバーを分離して考えるということですが、だからといって必ずしもサーバーを分離する必要があるかといえばそういうわけでもありません。
要はサービスの設計においてこの3つは同じ粒度で区別して設計しましょうというのが3層アーキテクチャの肝です。
なので、例えばwebサーバーの中でアプリケーションのロジックを扱っていても、あるいはAPIサーバーとDBサーバーが同じサーバー上にあっても、これらを分けて設計しているのであれば3層アーキテクチャと言ってもいいと思います。
一見すると世の中のアプリケーションのほとんどはこの3層アーキテクチャを取っているようにも思えます。
というのもwebサーバー、アプリケーションサーバー(APIサーバー)、dbサーバーは最も主要なサーバーの3つですし、逆にこれ以上要素を増やしてしまうと特定のサービスに特化した構成になってしまいそうです。
そんな中で、第4の構成要素を考える人々が現れ始めました。
この第4の要素というのがドメインです。
ドメイン駆動設計(DDD)
ドメインって何
ドメインとは何者なのか?といいますと、「サービス領域のルール・概念・ロジック」のことです。
たとえばECサイトにおけるドメインは商品、カート、ユーザーなどの概念(ドメインオブジェクト)や”商品を買う”、”カートにアイテムを入れる”、”ユーザーがログインする”などのロジック(ドメインロジック)です。
一見するとこれはビジネスロジックと同じもののように見えますが、ドメイン層がドメインオブジェクトの情報を書き換える処理を行うのに対し、ビジネスロジック層はどちらかというとUI層からの入力を整形するなどドメインオブジェクトと直接関係しないロジックを扱います。
このようなドメインを第4の要素として取り入れたアーキテクチャとしてレイヤードアーキテクチャが知られています。
レイヤードアーキテクチャは以下のように3層アーキテクチャのビジネスロジック層とデータアクセス層の間にドメイン層を設けた、いわば4層アーキテクチャです。
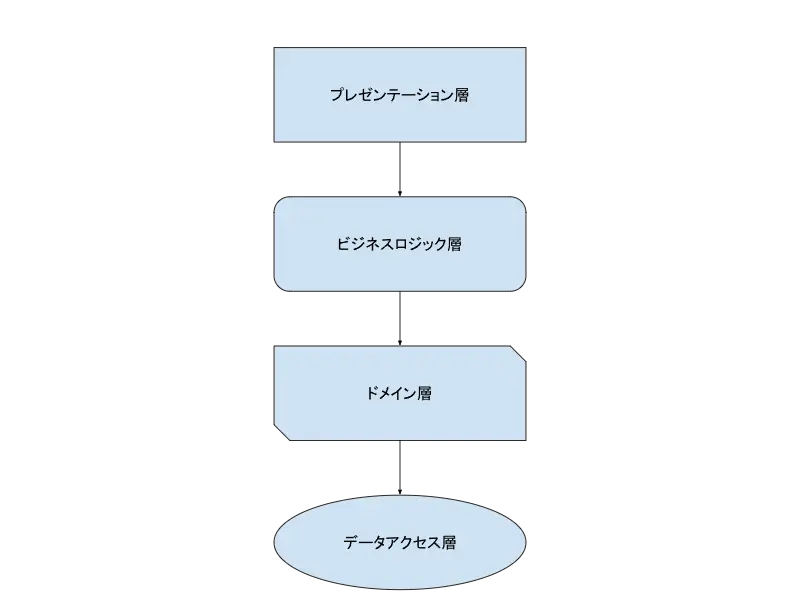
そして、図にあるように下の層は上の層に依存しないというルールを設けます。(上の層が下の層に依存するのはあり)
なぜこんなルールを設けるかと言いますと、これによって関心事を分離できるためです。
例えば、Webで実装されているサービスをネイティブアプリでも提供したいとなったらUIだけを変更したくなると思います。
もしUIがビジネスロジック層以下に依存してしまうとそこにまで手を加えないとUIの変更ができないということになってしまいます。
しかし、先程のルールを設けておくことで、UIだけを取り替えれば済みます。
このように、関心事を分離することでアプリケーションの柔軟性を高められるわけです。
ただ、問題は依存関係です。
上の図のアーキテクチャだとデータアクセス層は他の層に依存せず、ドメイン層はデータアクセス層に依存します。
これによって例えばデータの保存場所をRDSからAWSのDynamo DBに変更したりするとドメイン層はこれに伴って変更する必要が生じてしまいます。
このようなことを避けるために考案されたのがドメイン駆動設計です。
”駆動”設計ってなに?
ドメイン駆動設計というのは簡単に言うと、「ドメインをいちばん大事にして作った設計」のことです。
ドメインを大事にするというのはどういうことかというと、ドメインを他の要素に依存させないということです。
上述した通り大事にすることと依存させないことは同じです。
もう一度例を出しますと、例えばA、Bという2つの要素があってAがBに依存している(A -> B)という状況を考えます。
この際、仮にBが壊れたとするとBに依存するAも一緒に壊れてしまいます。
なので、Bの実装を変更しようとすると、それに依存するAの実装も変更する必要が出てきてしまいます。
このように、依存関係が増えるということはそれだけ壊れやすくなり、また変更に対する柔軟性も小さくなるということです。
また、逆に依存関係を持たせないということはいちばん大事な要素の実装の自由度を最大化できるということでもあります。
このような理由から、大事な要素は自分より大事じゃない要素には依存させないというのが大原則となっています。
ちなみに、これは依存性逆転の原則と呼ばれたりするやつで、SOLID原則のD(Dependency Inversion)に相当するものです。
「なんで逆転?」と思うかもしれませんが、これは後ほど説明するのであまり気にしなくて大丈夫です。
このような観点から見ると上述したレイヤードアーキテクチャはDDDにはなっていないことがわかります。
というのも、上で説明している通りレイヤードアーキテクチャはドメインがインフラストラクチャ(DBなど)に依存してしまっておりドメインを”一番大切”にできていないからです。
ではどうすればドメインを一番大切にできるのか?というところで出てくるのが例の依存性逆転の原則です。
依存性逆転の原則
依存性逆転の原則とは先程説明したように大事な要素は自分より大事じゃない要素には依存させないというルールのことと、一般的には説明されます。
その一方でこのルールに則るためのテクニックのことも、依存性逆転の原則と言ったりします。
ここではこのテクニックについて説明していこうと思います。
最も重要なのは仲介役(インターフェース)を作って、こいつに依存させるということです。
これだけ聞くと「??」だと思うので具体例で説明します。
例えばECサイトのバックエンドをレイヤードアーキテクチャで実装するとしましょう。
このときドメイン層とインフラストラクチャ層(データアクセス層)は次のように実装することができます。
// domain/model/Product.ts
export class Product {
constructor(
private userId: number,
private name: string,
private price: number
) {}
}
// domain/usecase/GetProductUseCase.ts
import { ProductRepository, productRepository } from "../infrastructure/ProductRepository";
export class GetProductUseCase {
constructor(private productRepository: ProductRepository) {}
execute(id: number) {
const product = this.productRepository.findById(id)
console.log(product)
}
}
// infrastructure/ProductRepository.ts
import { Product } from "../domain/Product"
export class ProductRepository {
findById(id: number): Product {
// データベースへのアクセス(SQLなど)
const product = new Product(1, 'egg', 100)
return product
}
}
export const productRepository = new ProductRepository()
// run.ts
const getProductUseCase = new GetProductUseCase(productRepository)
getProductUseCase.execute(1)
-> Product { userId: 1, name: 'egg', price: 100 }
このコードについて少し解説します。
まずドメインとして商品を表すProductクラスを定義しています。
そしてProductを取ってくるという操作をGetProductUseCaseに定義しています。
ユースケースというのはクリーンアーキテクチャの言葉で、レイヤードアーキテクチャでいうところのアプリケーション層に対応します。
domainに関する操作のみ扱っているのでユースケースをドメインの中に入れ込んでいます。(そんなこと
していいの?と思われるかもしれませんが、一旦飲み込んでください)
次に、データベースなどからProductを取ってくる操作をProductRepositoryに定義しています。
repositoryは日本語で倉庫を意味し、その中でデータベース(瓶とか米俵とか?)にアクセスするというイメージっぽいです。
なのでレイヤードアーキテクチャでいうところのデータアクセス層だと思っておけば大丈夫です。
最後にrun.tsでGetProductUseCaseのexecute関数を実行しています。
さて、このコードは依存性逆転の原則に違反しています。
なぜなら、ドメイン層(GetProductUseCase)がデータアクセス層(ProductRepository)に依存しているからです。
GetProductUseCaseがinfrastructureをimportしていることに注目してください。
ではドメイン層をデータアクセス層に依存させないためにはどうすればよいでしょうか?
それを考えるために、依存関係を図解しながら整理していきます。
まず、現状の依存関係は下のように表されます。
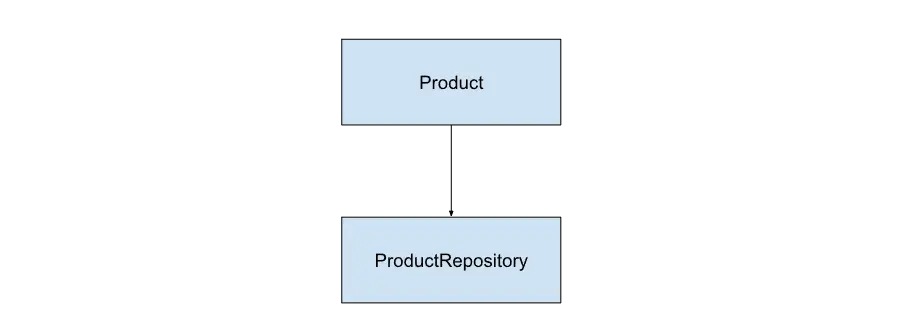
この依存関係を逆転するためには次のようにこれらのコードの仲介役を用意し、2つの層を両方この仲介役に依存させることで解決できます。
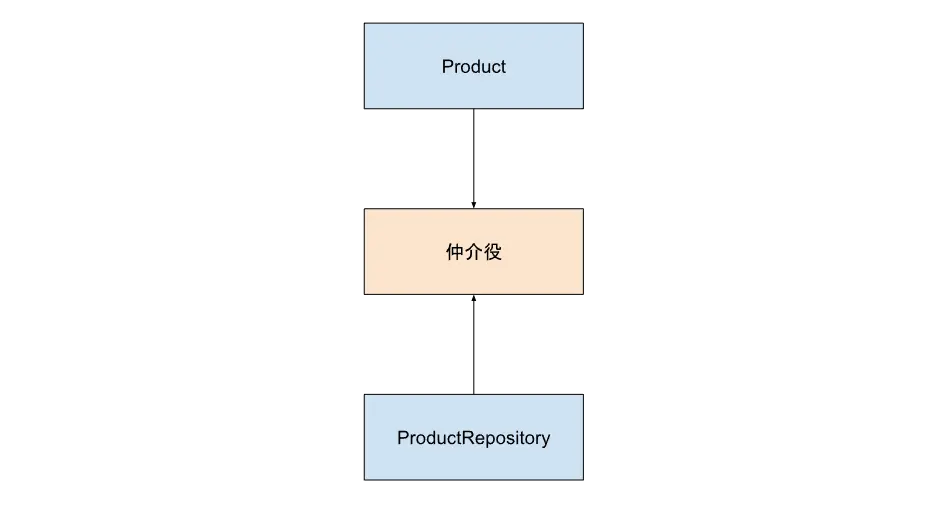
なぜこれで解決できるのか?というと、この仲介役をドメイン層に取り込むということができるからです。
つまり、以下のような解釈を行うことで依存性逆転の原則に則った実装を行うことができます。
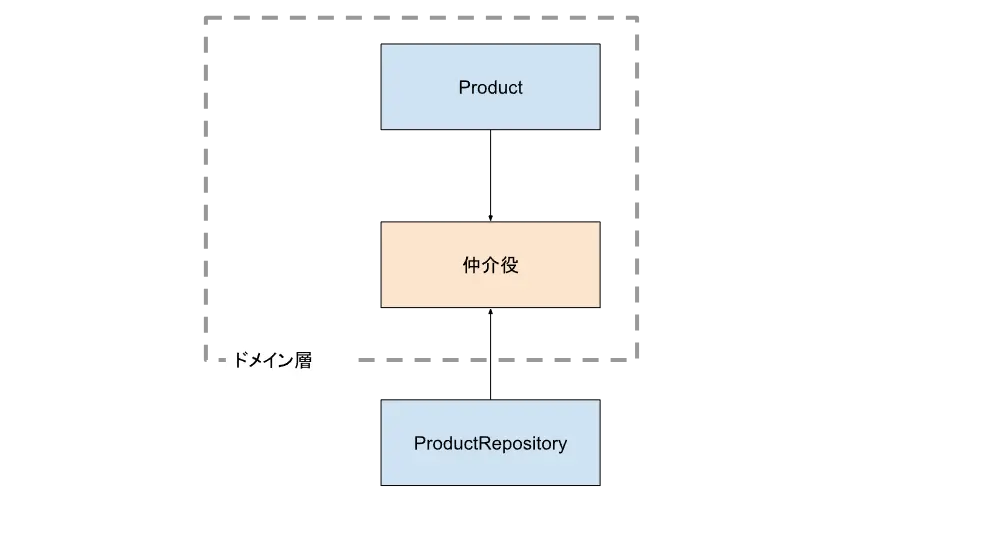
ではこの仲介役とは具体的には何なのでしょうか?
実はこれがデータアクセス層のインターフェースと呼ばれるものです。
インターフェースとは一言で説明すると抽象型のことです。
例えば上のProductRepositoryのインターフェースを実装するとすれば次のようになります。
// domain/repository/ProductRepository.ts
import { Product } from "../model/Product";
export interface IProductRepository {
findById(id: number): Product
}
さっきのProductRepositoryとの違いは実装を伴わない型であるということです。
こいつを使って先程のドメイン層とデータアクセス層を再実装してみます。
// domain/model/Product.ts
export class Product {
constructor(
private userId: number,
private name: string,
private price: number
) {}
}
// domain/usecase/GetProductUseCase.ts
import { IProductRepository } from "../repository/ProductRepository";
export class GetProductUseCase {
constructor(private productRepository: IProductRepository) {}
execute(id: number) {
const product = this.productRepository.findById(id)
console.log(product)
}
}
// infrastructure/ProductRepository.ts
import { Product } from "../domain/model/Product"
import { IProductRepository } from "../domain/repository/ProductRepository"
export class ProductRepository implements IProductRepository {
findById(id: number): Product {
// データベースへのアクセス(SQLなど)
const product = new Product(1, 'egg', 100)
return product
}
}
export const productRepository = new ProductRepository()
Productは先程と同じですが、それ以外の2つの実装に注目してみてください。
まず、先程はインフラストラクチャ層に依存していたGetProductUseCaseがドメイン層にのみ依存するようになっています。
そしてProductRepositoryがドメイン層に依存しており、確かに依存性が逆転していることがわかります。
実はクリーンアーキテクチャというのは今作った「依存性が逆転したレイヤードアーキテクチャ」の延長上にあるものに過ぎないのです。
ということでここからはいよいよクリーンアーキテクチャの説明に入ります。
クリーンアーキテクチャ
レイヤードアーキテクチャを変形
クリーンアーキテクチャを理解するために先程の「依存性が逆転したレイヤードアーキテクチャ」を改めて図解してみます。
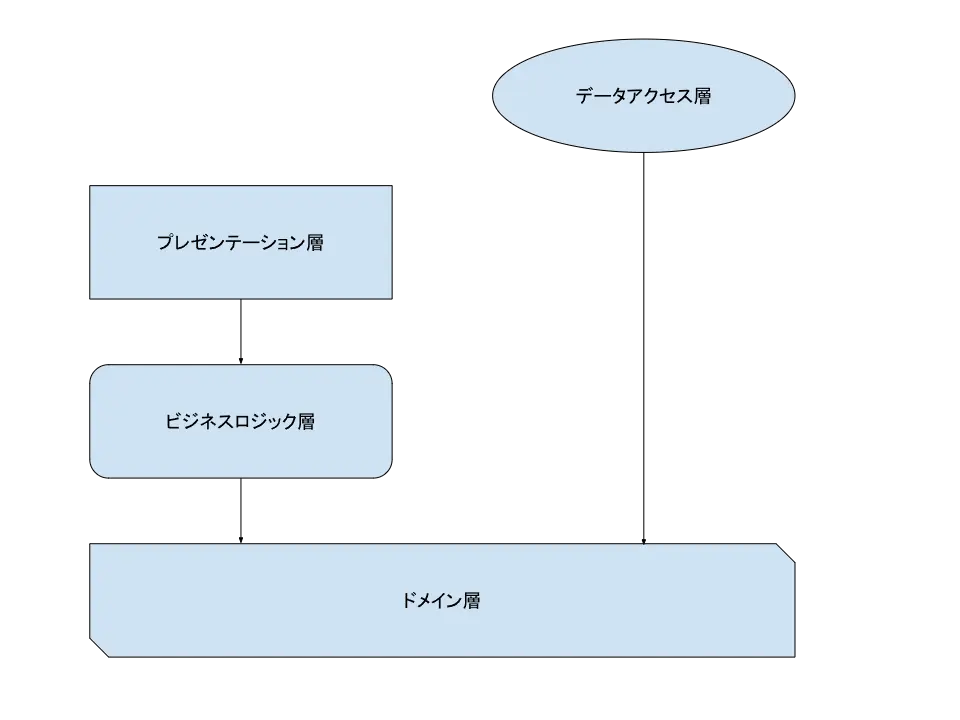
ここで、インフラストラクチャ層は一番上にしてみました。
そしてこれらの層をぐいっと延ばして丸めてみましょう。
ついでに色もつけてみましょう。
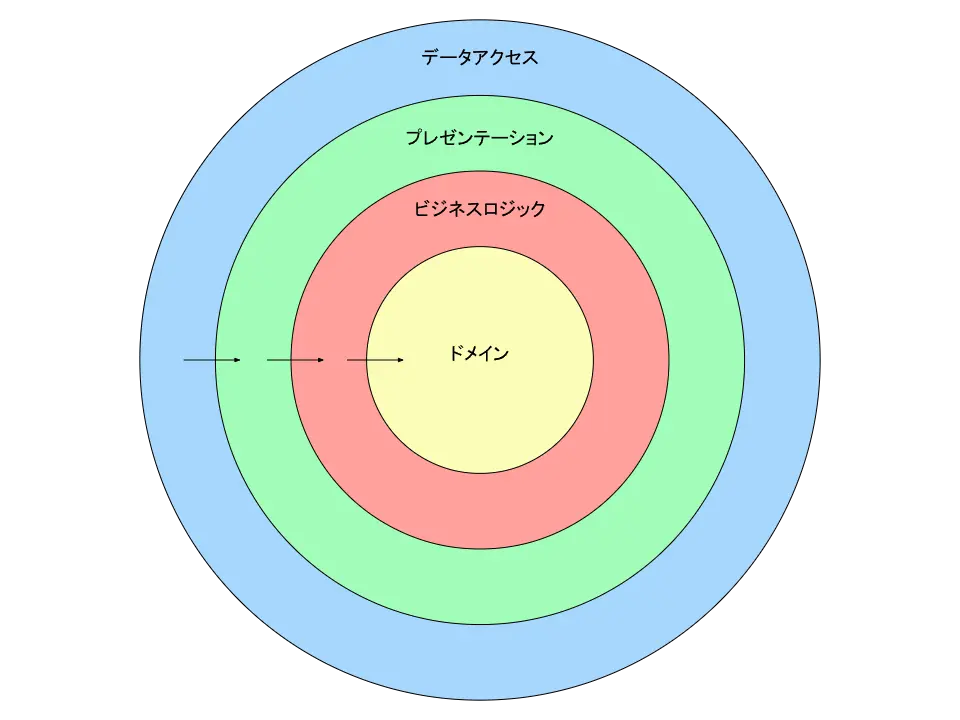
どこかで見たことがあると思ったら、実は有名なクリーンアーキテクチャの図に酷似していることが分かるかと思います。
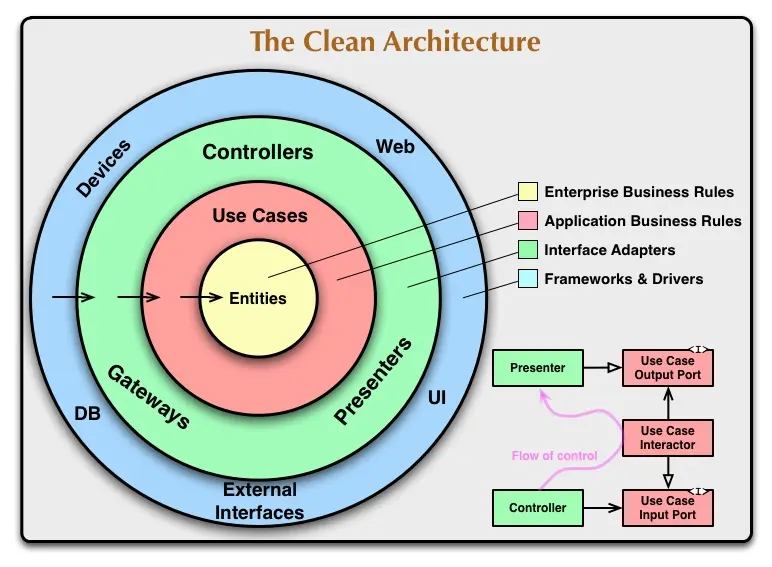
ただ、実際のソフトウェアに出てくる要素を今回紹介した4つの要素(プレゼンテーション、ビジネスロジック、ドメイン、データアクセス)だけで説明しようとするのはかなり乱暴です。
そこで、クリーンアーキテクチャではこれらの要素をそれぞれ細かく分解しています。
クリーンアーキテクチャの各要素
クリーンアーキテクチャが理解しにくい大きな要因として人によって解釈も使う言葉も違うということが挙げられます。
これによってgithubで実装例を見てみても何がなんだかわからないというケースが非常に多いです。
なので、ここではクリーンアーキテクチャでよく使われる単語、特に実際の実装例でよく使われている言葉を解説していきます。
先程の図でも記載があった基本となる4つの円の名前とそこに属する要素の名前を順番に覚えていきましょう。
ここに書かれている要素が分かればなんとなーく実装が読めるようになっていくと思います。
Enterprise Business Rules
一番内側の円です。
ここではドメインオブジェクトの定義やドメインを直接触るロジック(ドメインサービス)の定義を行います。
これらは一般にdomainやcoreというディレクトリの中に実装されるケースが多いです。
また、その中でもドメインオブジェクトはentityや model、ドメインサービスはserviceとして実装されているのをよく見かけます。
Application Business Rules
二番目に内側の層です。
ここではアプリケーションのロジックを扱います(レイヤードアーキテクチャのビジネスロジック層)。
実装例においてはapplicationなどの名前でディレクトリが切られているのをよく目にします。
また、クリーンアーキテクチャではこのようなロジック全般のことをUse Caseと呼んだりします。
なので、そのままusecaseというディレクトリが切られていることも多いです。
クラス名にはほぼほぼUseCaseという単語が使われています。
稀にServiceという単語が使われていたり、あるいは実装はServiceという名前でインターフェースはUseCaseなんていうこともあります。(ややこしすぎ)
Interface Adapters
内から三番目、外から二番目の層です。
ここではアプリケーションと外部(UIやデータベース)との橋渡しを行います。
具体的にはデータの変換が重になるかと思います。
ディレクトリとしてはadapter、controller、presenterなどの名前で切られていることが多い気がしますが、たまにapplicationの中にあったりもして結構自由です。
クラス名はほとんどがControllerでそれに付随するTransformer等がある場合もあります。
Frameworks & Drivers
一番外の層です。
フレームワークやデータベースドライバなど自分が実装した以外のコードを使いたいときはここで使います。(とはいえ殆どの場合でControllerなんかにもフレームワークの影響は及んでしまうのですが...)
一番良く見るディレクトリは上でも出てきたrepositoryです。
repositoryはクラス名にも使われます。
この他にデータベースアクセスのためのディレクトリにはpersistenceやデータベース名(mysqlなど)が多い気がします。
まとめ
今回はクリーンアーキテクチャについて超ざっくりな説明を行いました。
私もまだまだ理解が浅い部分もありますし、そもそもクリーンアーキテクチャの原本を読んでないので、次のアクションはこの本を読むことになりそうです。
ともあれ、この記事を通してなんとなくでもクリーンアーキテクチャを理解していただける方が一人でもいらっしゃれば嬉しいです。
参考文献
↓依存性逆転の説明としてとてもわかり易いです。

↓単語の意味や実装例の解説がとても詳しく、参考になります

